

Zeichenkodierung
Die Kodierung und Darstellung von Schriftzeichen mit und auf dem Computer ist ein äußerst umfangreiches, kompliziertes, aber auch spannendes Thema. Gerade Webautoren, die täglich mit Texten der weltweiten elektronischen Kommunikation umgehen, müssen die Konzepte der Zeichenkodierung zumindest in den Grundzügen verstanden haben, um funktionierende Webseiten bauen zu können. Dieser Abschnitt gibt eine zum Teil vereinfachte, aber dennoch genügend tief gehende Einführung.
Dieser Text erschien ursprünglich im Rahmen meines Buches Einführung in XHTML, CSS und Webdesign.
100101010 – Am Anfang waren null und eins
Computer arbeiten nur mit Nullen und Einsen, sogenannten Binary Digits (Bits). Für den Menschen ist deren Ein- und Ausgabe mühsam. Er ist seine vertrauten Zeichen gewohnt: Buchstaben, Ziffern und Satzzeichen, aus denen dann Wörter, Sätze und Absätze entstehen.
Der Computer muss die eingegebenen Zeichen aus den unterschiedlichsten Alphabeten und Sprachen in Nullen und Einsen umwandeln. Dafür gibt es Tabellen, in denen Zeichenkodierungen beschrieben werden. Beispielsweise wird der Bit-Kombination 01000001 der Großbuchstabe »A« zugeordnet, 01000010 steht für »B«, 01000011 für »C« und so weiter. Damit können Mensch und Maschine kommunizieren.
Von Bits und Bytes, dezimal und hexadezimal
Für gewöhnlich werden acht Bits zu einem Oktett (octet) zusammengefasst, besser bekannt als »Byte«. Ein Oktett kann 256 Zustände beschreiben, in diesem Fall 256 unterschiedliche Zeichen.
Neben dem Dezimalsystem, unserem Zahlensystem zur Basis 10 mit den Ziffern 0 bis 9, müssen Webautoren das Hexadezimalsystem beherrschen. Dabei handelt es sich um ein Zahlensystem zur Basis 16. Es verwendet die Ziffern 0 bis 9 und für die dezimalen Zahlen 10 bis 15 die »hexadezimalen Zahlen« A bis F. Die binäre Zahl 01000001 hat dezimal den Wert 65 und hexadezimal 41, die binäre Zahl 01011010 hat dezimal den Wert 90 und hexadezimal 5A.
Bei der Umrechnung von binär, dezimal und hexadezimal hilft der in Windows mitgelieferte Rechner in der wissenschaftlichen Ansicht oder der Rechner von Mac OS X unter Verwendung des Menüeintrags Darstellungsformat.
Oftmals wird die Hexadezimalschreibweise durch das Voranstellen von x (in XHTML) oder 0x (in Programmiersprachen wie C++ oder Java) kenntlich gemacht, also etwa x41, damit eine Verwechslung mit der Dezimal- oder anderen Schreibweisen ausgeschlossen wird.
Begrifflichkeiten
Der Begriff Zeichenvorrat (character repertoire) beschreibt eine endliche, nicht leere, ungeordnete Menge aller Zeichen, die man zur Verfügung hat oder verwenden möchte.
Der Zeichenvorrat lässt sich anordnen, die Zeichen also in eine Reihenfolge bringen und durchnummerieren. Dann spricht man von einem Zeichensatz (character set).
Um mit Zeichen arbeiten zu können, muss der Computer die Darstellung in Bits kennen. Dafür ist die Zeichenkodierung (character encoding), oder kurz einfach Kodierung (encoding, coding), zuständig. Da im Zeichensatz bereits Reihenfolge und Nummerierung festgelegt wurden, braucht man also nur noch die Bit-Muster zuzuordnen.
Einige Zeichenkodierungen können nur wenige Zeichen kodieren, andere ein paar mehr und wieder andere schließlich alle. Im Allgemeinen kodieren zwei verschiedene Zeichenkodierungen dasselbe Zeichen in unterschiedliche Byte-Sequenzen und dieselbe Byte-Sequenz in unterschiedliche Zeichen.
Zeichenkodierungen
US-ASCII
US-ASCII ist die grundlegende und daher wohl auch am weitesten verbreitete Zeichenkodierung, jedoch auch eine der am wenigsten umfangreichen. US-ASCII wird seit Ende der 1960er verwendet und ist eine 7-Bit-Kodierung, umfasst also 128 Zeichen.
Die ersten 32 Zeichen (von Position 0 bis 31) sind Steuerzeichen, ebenso das letzte auf Position 127. Steuerzeichen sind zum Beispiel für die Kontrolle von Bildschirmdarstellung und Druckern zuständig oder können bestimmte Editierfunktionen auslösen.
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 30 | ! | „ | # | $ | % | & | ‚ | |||
| 40 | ( | ) | * | + | , | – | . | / | 0 | 1 |
| 50 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | : | ; |
| 60 | < | = | > | ? | @ | A | B | C | D | E |
| 70 | F | G | H | I | J | K | L | M | N | O |
| 80 | P | Q | R | S | T | U | V | W | X | Y |
| 90 | Z | [ | \ | ] | ^ | _ | ` | a | b | c |
| 100 | d | e | f | g | h | i | j | k | l | m |
| 110 | n | o | p | q | r | s | t | u | v | w |
| 120 | x | y | z | { | | | } | ~ | |||
Die druckbaren US-ASCII-Zeichen beginnen an Position 32 mit dem Leerzeichen, dann folgen einige Satz- und Sonderzeichen, ab Position 48 die Ziffern beginnend mit »0«, das große »A« (65) bis »Z« (90) und das kleine »a« (97) bis »z« (122). Zwischen diesen Blöcken befinden sich immer wieder einige Satz- und Sonderzeichen. Das letzte druckbare Zeichen ist die Tilde (~) an Position 126.
Mit US-ASCII können Sie schon viele Texte elektronisch niederschreiben, vor allem englischsprachige, wenngleich hier auch nicht alle wünschenswerten Zeichen, wie typografische Anführungszeichen oder Gedankenstriche, zur Verfügung stehen. Für nicht englische Sprachen ist US-ASCII wenig geeignet, da zum Beispiel nicht einmal die in der deutschen Sprache wichtigen Umlaute vorhanden sind.
Die ISO-8859-Familie
Da US-ASCII für nicht englische Sprachen nur einen Teil der benötigten Zeichen enthält, wurde (unter vielen anderen) die ISO-8859-Familie standardisiert.
Die ISO-8859-Familie besteht aus 15 8-Bit-Zeichenkodierungen, in denen besonders europäische Sprachen gut dargestellt werden können: ISO-8859-1 bis ISO-8859-16, wobei es ISO-8859-12 nicht gibt. Die ersten 128 Zeichen (0 bis 127) entsprechen dabei US-ASCII.
- ISO-8859-1 (Latin 1): Westlich/Westeuropäisch
- ISO-8859-2 (Latin 2): Zentraleuropäisch, Osteuropäisch
- ISO-8859-3 (Latin 3): Südeuropäisch, Maltesisch, Esperanto
- ISO-8859-4 (Latin 4): Nordeuropäisch
- ISO-8859-5: Kyrillisch, Slawisch
- ISO-8859-6: Arabisch
- ISO-8859-7: (modernes) Griechisch
- ISO-8859-8: Hebräisch
- ISO-8859-9 (Latin 5): Türkisch
- ISO-8859-10 (Latin 6): Nordisch (Sámi, Inuit, Isländisch)
- ISO-8859-11: Thai
- ISO-8859-13 (Latin 7): Baltisch (»baltischer Rand«)
- ISO-8859-14 (Latin 8): Keltisch
- ISO-8859-15 (Latin 9): ähnlich ISO-8859-1, mit acht Änderungen (beispielsweise €-Symbol)
- ISO-8859-16 (Latin 10): Albanisch, Kroatisch, Englisch, Finnisch, Französisch, Deutsch, Ungarisch, irisches Gälisch, Italienisch, Lateinisch, Polnisch, Rumänisch, Slowenisch
Alle diese Zeichensätze enthalten an Position 160 (xA0) ein geschütztes Leerzeichen, an dem im Textfluss nicht umbrochen wird. Die nachfolgenden Positionen unterscheiden sich zum Teil sehr stark. An Position 173 findet sich in der Regel der Trennungsstrich. Allgemein wird ein Zeichensatz als passend für eine Sprache benannt, wenn alle für die Sprache benötigten Buchstaben enthalten sind. Jedoch fehlen dann oftmals immer noch typografisch korrekte Satzzeichen.
Viele Zeichenkodierungen dieser Familie eignen sich für deutschsprachige Texte, da in ihnen Umlaute und das »ß« vorhanden sind, nämlich ISO-8859-1, -2, -3, -4, -9, -10, -13, -14, -15 und -16. Benötigen Sie auch noch die in deutschen Texten seltener vorkommenden Buchstaben »À«, »à«, »É« und »é«, verkürzt sich die Liste auf -1, -3, -9, -14, -15 und -16. Durch diese Vielseitigkeit können Sie auf einer Website in der entsprechenden Kodierung zum Beispiel deutschen zusammen mit polnischem Text (ISO-8859-2, -13 oder -16) schreiben oder Deutsch und Türkisch gemeinsam (ISO-8859-9). Allerdings stoßen Sie auch schnell an die Grenzen: ISO-8859-5 enthält neben US-ASCII nur kyrillische Zeichen, -6 arabische, -7 modernes Griechisch und -8 Hebräisch. Diese können Sie weder untereinander noch mit beispielsweise Deutsch und dessen Umlauten kombinieren.
ISO-8859-1 ist die für Deutsch am weitesten verbreitete Zeichenkodierung. Sie bietet die nötigen Umlaute samt Eszett (ß) sowie die in der deutschen Sprache verwendbaren französischen Anführungszeichen (», Zeichennummer 187, und «, Zeichennummer 171). Das später eingeführte ISO-8859-15 wurde gegenüber ISO-8859-1 auf acht Positionen verändert, um unter anderem das Euro-Symbol zur Verfügung zu stellen.
Schöne Typografie ist mit ISO-8859-1 (oder anderen Zeichenkodierungen der Familie) jedoch nicht oder nur eingeschränkt möglich, da zwar die nötigen Buchstaben vorhanden sind, aber andere häufig genutzte (Satz-)Zeichen wie doppelte und normale Anführungszeichen (»Gänsefüßchen«, einfach und doppelt), Apostroph, Gedankenstrich und Auslassungszeichen (Ellipse) nicht existieren. Müssen oder wollen Sie in einer ISO-8859-Zeichenkodierung bleiben, müssen Sie für (schöne) Typografie auf Zeichenreferenzen ausweichen.
Unicode
Das Unicode Consortium setzte sich im Jahr 1991 das Ziel, als Zeichenvorrat möglichst jedes Zeichen, das in irgendeiner Sprache verwendet wird oder wurde (und dazu noch jede Menge zusätzlicher Symbole wie zum Beispiel mathematische Zeichen, Lautschrift, geometrische Formen, Pfeile sowie Musiknotation), aufzunehmen, zu katalogisieren und in geeigneten Kodierungen zur Verfügung zu stellen, die nicht mehr 128 oder 255 mögliche Positionen und damit Zeichen enthalten, sondern anfänglich 65.536 und später dann über eine Million.
Die ersten 256 Zeichen aus Unicode sind die Zeichen aus ISO-8859-1 in der entsprechenden Reihenfolge und damit die ersten 128 Zeichen aus US-ASCII. Allerdings werden sie je nach gewählter Kodierung anders als Nullen und Einsen abgespeichert. Den gesamten Zeichenvorrat können Sie in den Code Charts auf der Unicode-Website unter anderem als PDF anschauen.
Irgendwie müssen nun diese Tausende von Zeichen in Unicode dem Computer in Nullen und Einsen verständlich gemacht werden. Dafür gibt es mehrere Kodierungen, die jeweils kleine Vor- und Nachteile bieten. Für Webautoren ist vor allem UTF-8 interessant.
UTF-8 (8-bit Unicode Transformation Format) ist eine 8-Bit-Kodierung. Besondere Bit-Kombinationen am Anfang eines Oktetts sagen dem Computer, dass eine bestimmte Anzahl nachfolgender Oktette zusammen betrachtet werden muss, um ein Zeichen ergeben zu können. Die Zeichen aus US-ASCII werden deshalb in UTF-8 in genau einem Oktett kodiert, die Tausende von nachfolgenden Zeichen in zwei, drei oder vier Oktetten.
Deshalb ist Unicode nicht mit dem 8-bittigen ISO-8859-1 kompatibel, obwohl auf den ersten 256 Positionen die gleichen Zeichen stehen – die Positionen werden anders in Nullen und Einsen dargestellt. So bringt man alle Unicode-Zeichen in einer 8-Bit-Kodierung, eben UTF-8, unter.
Noch mehr Zeichenkodierungen
Die hier vorgestellten Zeichenkodierungen sind die in unseren Breiten am häufigsten genutzten und die für Webseiten am besten geeigneten. Es gibt Dutzende weiterer, die mehr oder weniger oft verwendet werden. Dazu gehören ältere und »unschöne« Kodierungen von Computerherstellern wie IBMs EBCDIC oder Apples MacRoman – oder auch die weit verbreiteten Zeichenkodierungen der Windows-Familie, die in Microsofts Betriebssystemen ihre Heimat haben und quasi Obermengen der ISO-8859-Zeichenkodierungen darstellen.
So enthält die bei der IANA registrierte Zeichenkodierung Windows-1252 alle Zeichen von ISO-8859-1 auf den entsprechenden Positionen, jedoch zusätzlich im Bereich 128 bis 159, der in den ISO-8859-Standards für Steuerzeichen reserviert ist, weitere Zeichen. Darunter befinden sich unter anderem auch typografische Anführungszeichen, Gedankenstriche, das Auslassungszeichen und das Euro-Symbol.
Selbst das oberflächliche Betrachten von in bestimmten Teilen der Welt weit verbreiteten Zeichenkodierungen, wie KOI8-R für Russisch beziehungsweise Shift-JIS, ISO-2022-JP oder EUC-JP für Japanisch, würde den Umfang dieser Einführung und vermutlich auch Ihr Interesse an diesem Thema sprengen. Es ist aber wohl schon durch diese kurze Einführung klar geworden, dass es zahlreiche Zeichenkodierungen gibt und die Existenz der »universellen« Zeichenkodierung UTF-8 einiges zu vereinfachen vermag.
Das Problem mit Zeichenkodierungen
Warum muss sich ausgerechnet ein Webautor mit diesen Dingen beschäftigen? Das Problem besteht darin, dass ein Computer nur die Nullen und Einsen, die Bits, sieht. Er kann nicht entscheiden, ob eine Bit-Kombination ein Zeichen aus ISO-8859-n, Windows-125n, MacRoman, KOI8-R oder UTF-8 beschreibt. Benutzerprogramme wie Browser oder Texteditoren müssen mitgeteilt bekommen, nach welcher Kodierung die Bits zu Zeichen aufgelöst werden sollen.
Geschieht das nicht, etwa weil der Webserver dem Browser keine oder eine falsche Kodierungsinformation mitliefert, erscheint auf dem Monitor Zeichenmüll. Ein Dokument, das ISO-8859-5-Zeichen enthält, zum Beispiel russischen Text, aber als ISO-8859-1 geöffnet wird, zeigt statt des kyrillischen großen F ein »Ä« an, da diese Zeichen auf der gleichen Position in beiden Zeichensätzen stehen. Wird ein in UTF-8 gespeicherter deutscher Text mit Umlauten als ISO-8859-1 geöffnet, werden statt eines Umlauts gleich zwei wirre Zeichen erscheinen, da in UTF-8 Umlaute mit zwei Oktetten kodiert werden, in ISO-8859-1 aber ein Zeichen regelmäßig mit genau einem.

»Einige süße Umlaute schmücken dieses Sätzchen – schön, oder?«, in UTF-8 gespeichert, als ISO-8859-1 aufgerufen
Sie müssen immer explizit angeben, vor allem beim erstmaligen Speichern einer Datei, mit welcher Kodierung Sie arbeiten. Verwenden Sie daher einen Text- oder HTML-Editor, der mit unterschiedlichen Kodierungen umzugehen versteht, aber wenigstens US-ASCII, die ISO-8859- und Windows-125n-Familien sowie UTF-8 unterstützt, da diese in unseren Gefilden die am weitesten verbreiteten Kodierungen sind. Abbildung 2.21 zeigt, wie Sie Dokumente im Editor UltraEdit korrekt als UTF-8 (ohne BOM) abspeichern.
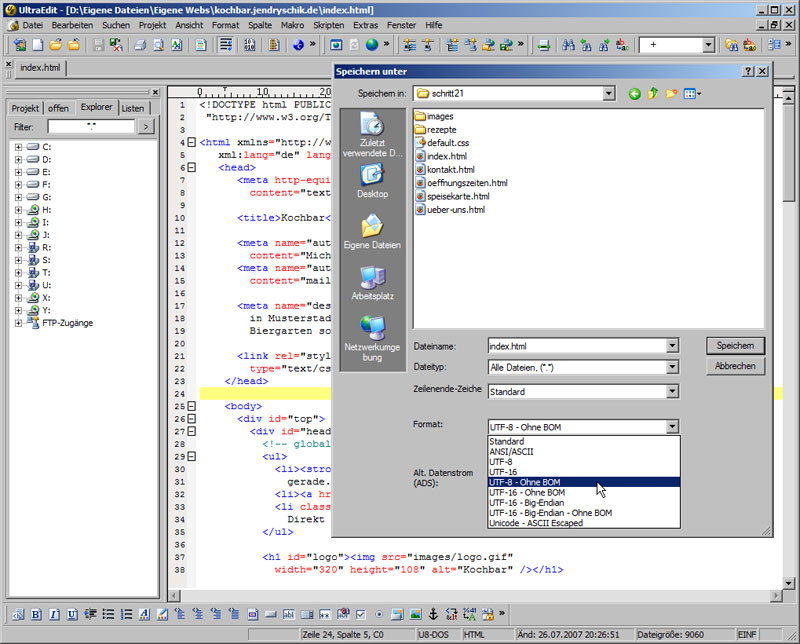
Dokumente mit UltraEdit als UTF-8 abspeichern
Auch bei der Auslieferung von Dokumenten durch den Webserver muss die richtige Kodierung bekannt sein. Wie Sie die Zeichenkodierung Ihres Webservers konfigurieren, können Sie in dessen Dokumentation nachlesen. Beim Apache HTTP Server beispielsweise geht dies sehr einfach über eine Zugriffskontrolldatei (.htaccess-Datei) und dem Eintrag der verwendeten Zeichenkodierung bei der Direktive AddCharset:
AddCharset UTF-8 .html .css AddCharset ISO-8859-1 .txt
.htaccess
Zugriffskontrolldateien werden auch .htaccess-Dateien genannt, denn es handelt sich dabei standardmäßig um Textdateien ohne Dateinamen mit der Dateiendung htaccess. Solche Dateien können Sie unter Windows nur über Umwege anlegen. Öffnen Sie einen Editor Ihrer Wahl (Notepad tut es auch) und speichern Sie ein leeres Textdokument einfach als .htaccess ab. Achten Sie darauf, dass der Editor nicht automatisch eine Dateiendung (z. B. txt) anhängt. Im unwahrscheinlichen Fall, dass sowohl die Anzeige der Endungen bei bekannten Dateitypen ausgeschaltet ist als auch Dateien vom Typ .htaccess mit einem Programm verknüpft sind, blicken Sie im Windows Explorer ins Leere, aber keine Sorge, die Datei ist natürlich vorhanden und kann problemlos per FTP auf den Webserver hochgeladen werden.
Bei .htaccess-Dateien ist es wichtig, dass Sie auf den korrekten Zeilentrenner achten. Da der Apache zumeist auf einem Unix-System läuft, ist der korrekte Zeilentrenner das Zeichen Zeilenvorschub (U+000A). Wenn Sie unter Windows oder Mac arbeiten, sollten Sie einen Editor verwenden, der die Wahl des Zeilentrenners erlaubt, oder Sie übertragen die Datei im FTP-Programm im ASCII-Modus, wodurch die Zeilentrenner automatisch richtig konvertiert werden. Übertragen Sie die Datei jedoch mit einem falschen Zeilentrenner, kann das unter Umständen die ganze Website außer Funktion setzen.
- Apache HTTP Server Version 1.3 – .htaccess files
Englischsprachige Einführung in die Zugriffskontrolldatei.htaccessfür Apache 1.3. - Apache HTTP Server Version 2.0 – Apache Tutorial: .htaccess files
Englischsprachige Einführung in die Zugriffskontrolldatei.htaccessfür Apache 2.0.
Zeichendarstellung
Ob gewisse Zeichen überhaupt angezeigt werden können, hängt vom Betriebssystem, der Anwendungssoftware (Webbrowser, Texteditor) und den installierten Schriften ab. Die auf dem lateinischen Alphabet basierenden Zeichenkodierungen wie US-ASCII oder ISO-8859-1 lassen sich im Allgemeinen problemlos auf jedem Rechner verwenden. Auf einigen Systemen mag es Schwierigkeiten mit komplexeren Alphabeten geben; die umfangreichen japanischen oder chinesischen Schriftzeichen sind dafür Kandidaten. Aber in der Regel sind bei der Zielgruppe dieser Schriftzeichen – eben Personen, die dieser Sprachen mächtig sind – Betriebssysteme entsprechend ausgestattet und eingestellt. Sollte ein Zeichen nicht angezeigt werden können, wird stattdessen zumeist ein Fragezeichen oder ein Rechteck verwendet.
Intelligente, halbwegs aktuelle Webbrowser holen sich ein Schriftzeichen, das in der gerade verwendeten Schriftdatei nicht vorhanden ist, aus irgendeiner anderen Schriftdatei auf dem Rechner, sofern das Zeichen dort vorkommt. Sie müssen also keine Angst haben, wenn in der von Ihnen vorgegebenen Schriftfamilie ein Zeichen nicht verfügbar sein sollte, solange es in einer anderen auf allen Rechnern standardmäßig installierten Schriftdatei aufzufinden ist.
Leider finden sich unter den vielen Tausenden von Zeichen aus Unicode immer welche, besonders Nicht-Schriftzeichen, die nicht durch die diversen mitgelieferten Schriften eines Betriebssystems abgedeckt sind. Diese Symbole sind aber meistens recht selten und für das Verständnis eines normalen Texts nicht notwendig (bei zum Beispiel mathematischen Texten mag das anders aussehen, aber dafür ist XHTML auch keine geeignete Darstellungsform). Manche Browser oder Betriebssysteme fordern den Benutzer in solchen Fällen auf, entsprechende Schriften nachzuinstallieren. Hier hilft nur, wie überall in der Webentwicklung, ausführliches Testen auf unterschiedlichen Standardinstallationen – Betriebssystemen wie auch Browsern. Sollte der Test auf den verbreiteten (Ziel-)Systemen negativ ausfallen, sollten Sie Alternativen für das benötigte Zeichen ins Auge fassen: ein anderes passendes Zeichen aus Unicode oder eine Grafik, was jedoch andere Probleme mit sich bringen könnte (bei der Grafik zum Beispiel fehlende Skalierbarkeit oder möglicherweise andere Schrift).
Zeicheneingabe
Wie bekommen Sie nun die Zeichen in den Computer? Für die gewöhnlichen auf der Tastatur befindlichen Zeichen ist das kein Problem: einfach die entsprechende Taste drücken. Eventuell noch die Umschalt-Taste dazu. Für normale Texte reicht das erst einmal. Wollen Sie aber eine Selbstverständlichkeit wie ein Anführungszeichen oder ein Apostroph eingeben, dann gibt es schon ein Problem. Zwar existieren die generischen US-ASCII-Zeichen (“ und ‚), aber schön sind die nicht (siehe Typografie auf Websiten). Textverarbeitungsprogramme wie Microsoft Word oder OpenOffice.org Writer wandeln diese US-ASCII-Zeichen nach Eingabe in ansehnliche sogenannte Smart Quotes um, ein Texteditor in der Regel aber nicht. Dennoch können Sie auch diese Zeichen mehr oder weniger einfach eingeben. Ein Mac OS X-Rechner macht es dabei leichter als ein Windows-System. Tabelle 2.10 zeigt, welche Tasten Sie unter Windows und Mac OS X drücken müssen, um ein bestimmtes Zeichen zu erhalten.
| Zeichenname | Zeichen | Tastenkombination | |
|---|---|---|---|
| Windows | Mac OS X | ||
| Apostroph | ‚ | Alt+0 1 4 6 | altshift# |
| doppeltes Anführungszeichen unten | „ | Alt+0132 | alt^ |
| doppeltes Anführungszeichen oben | “ | Alt+0147 | alt2 |
| einfaches Anführungszeichen unten | ‚ | Alt+0130 | alts |
| einfaches Anführungszeichen oben | ‘ | Alt+0145 | alt# |
| französisches Anführungszeichen Anfang | » | Alt+0187 | altshiftq |
| französisches Anführungszeichen Ende | « | Alt+0171 | altq |
| einfaches französisches Anführungszeichen nach rechts | › | Alt+0155 | altshiftn |
| einfaches französisches Anführungszeichen nach links | ‹ | Alt+0139 | altshiftb |
| Gedankenstrich | – | Alt+0150 | alt- |
| geschütztes Leerzeichen | Alt+0160 | alt Leertaste | |
Die Tastenkombinationen von Mac OS X sind nach kurzer Eingewöhnungszeit gut zu merken. Es sind weniger Tasten zu drücken, und oft deutet auch die eigentliche Tastenbeschriftung schon die möglichen Zeichen an. Unter Windows ist es nicht ganz so einfach; dort müssen Sie die Alt-Taste drücken und währenddessen Ziffernkombinationen auf dem Nummernblock eingeben. Aber es gibt auch Software, mit der Sie unter Windows eigene Tastenkombinationen definieren können – zum Beispiel AllChars von Jeroen Laarhoven. Damit müssen Sie sich keine Zahlen mehr merken, um diese dann umständlich einzugeben.
Das betraf jetzt allerdings nur Satzzeichen für deutschsprachige Texte. Es gibt Situationen, in denen Sie mehr Zeichen benötigen. Dazu können Sie auf die Zeichentabelle (Windows) beziehungsweise Zeichenpalette (Mac OS X) zurückgreifen.
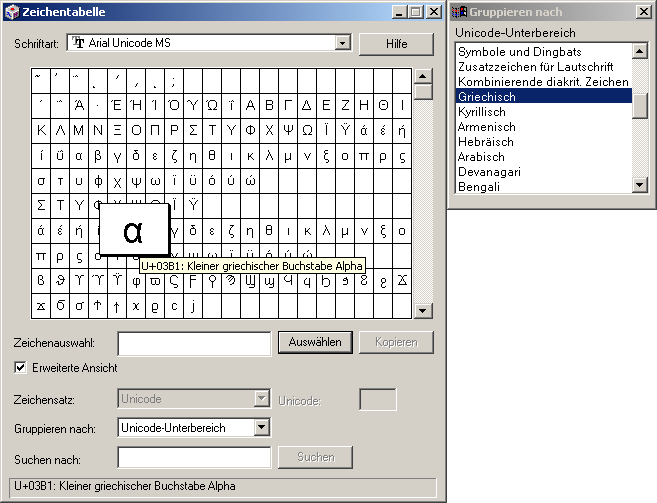
Zeichentabelle von Windows 2000, hier die Gruppe für Griechisch
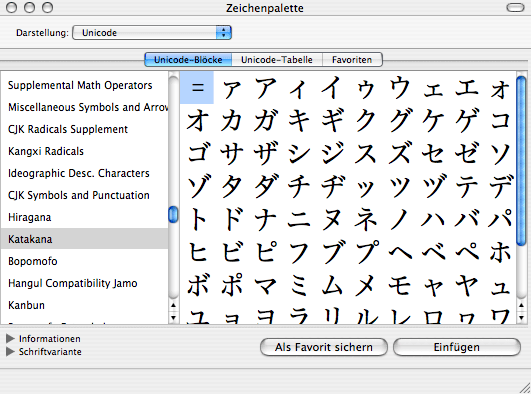
Zeichenpalette von Mac OS X, hier der Katakana-Block
Die Windows-Zeichentabelle finden Sie unter Start > Programme > Zubehör > Systemprogramme (sofern sie installiert wurde), die Mac OS X-Zeichenpalette unter Programme > Schriftsammlung > Bearbeiten > Sonderzeichen (seit 10.4 Tiger in fast allen Programmen unter Bearbeiten > Sonderzeichen) beziehungsweise unter dem Flaggensymbol in der Menüleiste, wenn Sie die folgenden Einstellungen vornehmen:
- Unter Mac OS X 10.3 Panther können Sie unter Systemeinstellungen > Landeseinstellungen > Tastaturmenü eine Tastaturübersicht mit der Möglichkeit zum Wechseln der Tastenbelegungen in die Menüleiste einblenden. (In früheren Mac OS X-Versionen fand sich eine Tastaturübersicht im Ordner Dienstprogramme des Programmordners.) In der Tastaturübersicht sehen Sie die gegenwärtige Tastenbelegung – drücken Sie auch die Tasten shift und alt, um weitere Belegungen zu sehen. Stellen Sie einfach mal andere Sprachen wie US-Amerikanisch, Französisch, Russisch, Türkisch oder Thailändisch ein, um andere Tastenbelegungen zu sehen. Sie können dann über Ihre Tastatur etwas mit der angezeigten Belegung eingeben. Es wird ein wenig ungewohnt sein, für die Eingabe kurzer Texte ist es jedoch durchaus geeignet. Komfortabler wird es nur noch, wenn Sie sich eine Tastatur mit der entsprechenden Belegung kaufen.
- In Windows können Sie Einstellungen zur Tastaturbelegung über Start > Systemeinstellungen > Ländereinstellungen im Register unter Eingabe vornehmen. Sie können mehrere Tastaturlayouts einrichten, die auf Wunsch in der Taskleiste oder mit bestimmten Tastenkombinationen aktiviert werden können.

Tastaturübersicht von Mac OS X für eine kyrillische Tastenbelegung

Windows-Bildschirmtastatur für eine englische Tastenbelegung
Die Wahl der »richtigen« Zeichenkodierung
Welche Zeichenkodierung sollen Sie nun verwenden, wenn Sie ein XHTML-Dokument schreiben? Die einfache Antwort: die passende.
Schreiben Sie einen englischen Text und brauchen dabei nur ab und zu typografisch passende Anführungszeichen oder ein Apostroph, können Sie US-ASCII als Zeichenkodierung wählen und diese Sonderzeichen als Zeichenreferenzen einfügen. Oder Sie verwenden UTF-8 und geben auch die Sonderzeichen direkt ein.
Wenn Sie einen Text auf Deutsch schreiben, kommen Sie um Umlaute und damit zum Beispiel ISO-8859-1 nicht herum. Auch hier können Sie für typografisch schöne Satzzeichen auf Zeichenreferenzen zurückgreifen. Oder Sie verwenden hier ebenfalls wieder direkt UTF-8.
Sollten Sie auf einer Seite verschiedene Sprachen und Schriftfamilien mischen wollen, werden Sie meistens um UTF-8 nicht herumkommen. Nur in wenigen Fällen, wenn Sie beispielsweise Deutsch und Türkisch (ISO-8859-9) oder Deutsch und Polnisch (ISO-8859-2, -13 oder -16) mischen wollen, kommen Sie ohne UTF-8 aus, sofern Sie eine Zeichenkodierung aus der ISO-8859-Familie nehmen und eventuell zusätzlich benötigte Zeichen als Zeichenreferenzen eingeben.

- HCD-Reifegrad steigern und Human-Centered Design in einer Organisation etablieren - 21. Januar 2024
- CPUX-Zertifizierungen für UX-Professionals und alle, die es werden wollen - 28. Juni 2023
- Lean UX in Ihrem Unternehmen - 7. Februar 2021
Hinterlasse einen Kommentar
An der Diskussion beteiligen?Hinterlassen Sie mir einen Kommentar!
Ihre Kommentareingaben werden zwecks Anti-Spam-Prüfung an den Dienst Akismet gesendet. Darüber hinaus nutze ich die eingegebene E-Mail-Adresse zum Bezug von Profilbildern bei dem Dienst Gravatar. Weitere Informationen und Hinweise zum Widerrufsrecht finden sich in der Datenschutzerklärung.